Introduction
The primary issue of importance for us is the low utilization of the ARQ protocols due to the timeout period. The solution is to pipeline the packets in the communication channel; have more than one unacknowledged packet at a time in the channel. The limitation is typically the amount of buffer space that the sender has available to store messages. Each message must be kept available until it is acknowledged. Given that network latencies could be on the order of seconds, and that data rates are often in the order of 10's of megabits per second, it is quite likely that the sender would run out of buffer space before the channel was completely full.The goal would be to send enough packets so that the first acknowledgement arrives just as the sender has sent the packet that fills up its buffer space, and then you would continue to send messages and receive acknowledgements continuously. The channel is completely utilized except for the packet overhead. Unfortunately there are a number of reasons why this won't happen:
- The sender may run out of buffer space and have to stop sending.
- There may not be enough traffic to keep the channel full.
- Network latency is not deterministic so even under the best of circumstances there will be times when long delays cause the sender to stop.
- Packets (data and acknowledgements) get delayed for extended periods, lost or corrupted. When this happens, timers expire, duplicate packets get sent and utilization decreases.
Typically, if we assume that the sender has an unlimited source of messages to send, the sender has insufficient buffer space to completely fill the channel, so it sends as many messages as it can and this group is called a flight. These messages arrive at the receiver and several ACK's are sent (depending on the arrival times and piggybacking options) which arrive back at the sender at about the same time. As the sender responds with more messages, they will again be grouped together. This process continues, interrupted of course by the need to send duplicates for one reason or another.
Properties
Most (probably all) SWP's are connection-oriented. This allows the endpoints to negotiate protocol parameters, including the window size, initial sequence numbers (you don't want to always start at zero) and a few other things. Also, since SWP's are reliable protocols, the setup or connection phase is important to insure that both ends agree to communicate and that both ends are who they are supposed to be (this is called authentication).Although most of the examples show SWP's with a sender and a receiver, they are almost always duplex, with both sides having a sender and a receiver. This is the source of piggybacking for ACKs anyway.
Since SWP's have acknowledgements and sequence numbers, they resolve all of the reliability issues except delayed packets. No matter what you do, you can't remove this completely as a problem. One method is to use large sequence numbers (32 or 64 bits) so that a sequence number can't be repeated for a long time. Then, an old packet (as indicated by a time stamp) can be identified and thrown away before it causes a problem. The reality is that this problem continues in very widely used protocols, such as TCP.
Utilization
Utilization for a sliding window protocol is similar to the calcuation for an ARQ protocol, which is:where
and
L = Message Length M = Data length C = Network latency Y = Resend cost R = Data rate T = Timeout value E = Probability of an error
What changes in the sliding window protocol is that instead of sending one message, the sender can send a window full, so if we ignore errors for the moment and let W be the window size in message-size buffers, the utilization is:
The amount of data sent is multiplied by the number of messages in a flight. The time between flights is simply the latency - the time for the first acknowledgement to arrive. For example, if L = 1000 bytes, B = 100 bytes, D = 0.2 s, 100 MBps (bytes per second) and W = 4 buffers:
If we increase the number of buffers we will get higher utilizations until we reach the point where the time to send a flight is exactly the network latency and utilization will be at a maximum. For example, if the number of buffers in the window is raised to 16:
If we take possible errors into account, we will want to find some sort of simple average to reduce the complexity of the calculations. If we use the approach used above, we simple calculate some cost of a resend, but is that accurate? Suppose one packet in a flight is lost; all of the others will be acknowledged, and it is possible that more messages will be sent as the ACK's arrive, but eventually, the sending stops waiting for the missing acknowledgement. Remember that the window can't move forward until all messages in the window are acknowledged. The sender will stop sending until the timer expires; it will send the duplicate, and it will wait for the ACK before going one. The pipeline can then be restarted.
While there are many possible scenarios, it is reasonable to assume that all errors result in a restart of the pipeline, which has a cost of sending the duplicate, waiting for the ACK and then resending an entire flight. If the probability of an error is E:
For any given flight, there is the probability of an error which has a particular cost. This expected cost can be included as a part of the expected total time or capacity to get the expected utilization, which is:
For example, suppose that in the previous example T is 0.3 s (somewhat larger than the latency) and that the probability of an error is 0.01. Then,
and the utilization is:
and for a window size of 16, the utilization is:
Handling Errors
One interesting issue in sliding window protocols is the handling of error conditions. There are two schemes:Go-Back-N
In this method, if the sender has a timeout, it assumes that all unacknowledged packets are unreceived and resends them all. This clearly chews up some network capacity, but if errors typically come in bursts, it might avoid waiting for each of the timeouts to occur individually. In the case where the receiver has a single buffer and doesn't accept packets out-of-order, it is certainly the best approach to take.Selective Repeat
In this method, the sender duplicates only the message that timed out. Its advantages and disadvantages are the reverse of those for Go-Back-N. This is the most widely used method, but many protocols allow the endpoints to negotiate this as an option.Byte-based SWP's
The book discusses only SWP's that are based on windows composed of buffers. Another possibility is to have a single buffer and let the window be a certain number of bytes. The advantages are that you don't have to worry about using fixed size buffers when traffic is often variable length, and you have very tight control of the amount of data that has to be managed. In a typical byte-based SWP, the window is described like this: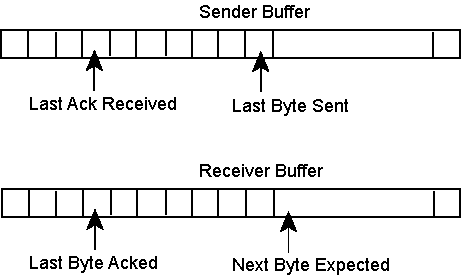
As with other SWP's there is a pointer for the beginning and end of the window on each end, with the window size equal maximum distance allowed between the pointers. The sender can send up to window-size bytes and then it is blocked until acknowledgements come in for the outstanding bytes. Similarly, the receiver can have up to the window size of the receiver bytes that have been received but not processed or acknowledged and then it is blocked.
Messages are not single bytes, but blocks of bytes that are efficient for network conditions. The sequence number is counted from the beginning of the connection, so if the sender was currently sending the 10,000th byte, the sequence number would be 10,000 more than the initial sequence number. If the message was 1000 bytes long, then the next message would be sequence number 11,000. As with buffer-based SWP's, the receiver ACKs with the next byte is expects to get.