Introduction
The Physical Layer is responsible for the actual transmission of data between nodes of a computer network. Based on the previous unit, this means that the physical layer is responsible for the transmission and receception of data signals and all of the associated activities, including access to the medium, multiplexing usage and error control. As you will see, the Physical Layer and the Datalink Layer are intimately connected and may as well not be separated in most instances.
There are many possible choices here: using a serial port or USB on a computer, a modem and telephone connection, Ethernets, token rings, SONET networks, wireless IEEE 802.11 and so on. While there are many choices, there are some features of these physical layer that are common and they can be roughly divided into three types: Local Area Networks (LAN), Wide Area Networks (WAN) and Metropolitan Area Networks (MAN).
LAN's typically cover a relatively small area and their primary function is to connect a large number of nodes together into a subnet. For example, all of the desktop systems in an office. In order to do this efficiently, most LAN's are multi-point, which means in effect, that transmissions by one node may be seen by many nodes ont he network. Sometimes this is referred to as a broadcast network.
WAN's typically move data over relatively long distances and they are point-to-point. Transmissions by one node go to one and only one other node.
MAN's are intermediate in nature and attempt to connect the nodes in a relatively large area (a diameter of tens of kilometers) into a subnet. For example, cable data access. MAN's typically have some type of broadcast characteristic, but due to the relatively long distances and large number of nodes, they need protocols that are different than those of LAN's.
The differentiation between these types not concrete. For example, two computers connected with a serial port are enjoying a point-to-point network, but it is not a WAN. Similarly, some types of physical layer protocols that might be used for a LAN, could also be used for a MAN.
Physical Layer Protocols Characteristics
The properties of physical layer protocols that you will see are:
1. Signaling method; digital or analog, what encoding method, what data rates, etc.
2. Physical organizaton; network topology; guided or unguided media, what specific attributes, how nodes are connected, maximum distances, etc.
3. Access Method; how a node access the media, is it shared and how is the sharing done.
4. Error control; how physical layer errors are handled.
5. Frame format; what data is required in the basic protocol unit and how is it organized.
In the OSI model, the last three are part of the Data Link layer. In general, this is not an effective way to view the division of activities, because they are intimately tied to the physical layer protocol and can't be treated as an independent layer anyway. In recogntion of that fact, the IEEE 802 standards (the Institute of Electrical and Electronic Engineers has been a leader in setting standards, and the 802 standards are their Local and Metropolitan Area Network standards) described this relationship as a physical layer with a Medium Access Control (MAC) layer. We won't make a huge distinction here, but in most cases, the last three of the list are part of the MAC layer.
For the sake of a definition, in the protocol stack, a unit of information that passes between two entities at the same level in the stack (those implementing the same protocol) call the data moving between the two a protocol data unit or PDU. These entities are also called frames or packets depending and any one of these terms is acceptable. The unit of data that moves between layers on the same node is called a service data unit or SDU.
Framing
If you sent a PDU between two nodes using a digital signal it would contain data represented by ones and zeros encoded with your particular scheme (RZ, NRZ, ...). The same is true of analog signaling. On the sending end, the transmitter would get the data to send and it would generate the necessary voltage levels for the signal starting at the first bit and continuing to the last bit. On the receiving side these signals would be sampled and converted to digital data and then passed to the higher layer protocols. Suppose that the PDU had the following format:

When this PDU arrives at the receiver the only indication that a PDU is coming is the first byte arriving. This could be a problem if the node doesn't interrupt and start the sampling soon enough, or if the clocks of the nodes are slightly out of synchronization. The receiver could miss a few bits and that could render the communication invalid. To avoid this, many protocols add synchronization bits to the beginning of the PDU.
Another problem is that the end of the PDU is indicated by the non-existance of bits on the media. If the communication is interrupted for some reason, the receiver might think that it had received the entire PDU, when it had not. In computer networking as in life, finding an error is far less damaging than having an error and not finding it. To avoid this problem, most protocols add something to the PDU to guarantee that the correct length is known. There are three possibilities, sentinels, counts and synchronous framing.
Error Control
Most data transmission systems are quite reliable, but even if the error rate is 1 in one trillion bits, that would amount to quite a few errors given the amount of data that is transmitted over most networks. Therefore, network protocols have to decide if they are going to be reliable and check for errors, or be unreliable and not bother checking. At first glance, not checking for errors seems unreasonable, but not all protocols need to do this. For example, suppose that you are writing an application and you know that the Transport Layer protocol is reliable; if you trust this layer, you really don't have to bother checking. This is one of the primary advantages of the layered architecture approach.
So what is typically meant by the term reliable:
- The arriving PDU's have no bit-level errors.
- The packets arrive in the order sent.
- No packets are delivered that aren't part of the data stream.
The tools to achieve these results go to the heart of protocol design and will be discussed at different points in later topics. However, one of the primary features of physical layer protocols is the first requirement - no bit-level errors. This is typically achieved with the use of checksums or cyclical redundancy checks (CRC's).
A CRC has a generating polynomial of the form:
Gn = dn-1xn-1 + dn-2xn-2 + ... + d0x0
For example, for n = 9, a generating polynomial might be:
G = 1x8 + 0x7 + 0x6 + 1x5 + 1x4 + 0x3 + 1x2 + 0x1+ 1x0
or
G = 100110101
The generating polynomial divides the binary message to determine the remainder which is then subtracted from the message to get a message that is evenly divided by the generating polynomial. At the receiving end, if the message divided by the generating polynomial yields a remainder, it must be corrupted. Both sides have to use the same generating polynomial. Also, so that no data in the message must be destroyed to subtract the remainder, n-1 zeros are added to the original message before dividing.
All arithmetic is done in one's complement form, so that there are no carries or borrows. One's complement arithmetic uses an exclusive or (XOR) to perform both addition and subtraction: (0+1) = (0-1) = 1.
For example, if the message is 100101001 and the generating polynomial is 10011, then:
- Append 4 zeros to the message (100101001,0000)
- Do one's complement polynomial division:
10001 1011 ---------------------------- 10011 | 100101001,0000 10011 -------- 11001 10011 -------- 10100 10011 -------- 11100 10011 ------- 11110 10011 ------ 11110 10011 ------ 1101 = remainder - Subtract the remainder form the message and send the result.
100101001,0000 1101 --------------- 1001010011101 = the message transmitted to the other end
You can check the result by dividing the transmitted message by the generating polynomial. It will be zero.
Access Control Methods
For a point-to-point network, access control is not a problem. The two endpoint nodes negotiate between themselves for access. For example, they can take turns based on a timing algorithm. This is called Time Division Multiplexing or TDM. Or they can divide the bandwidth and each can take part using FSK. For example, if the bandwidth is 1,000,000 Hz, one end can send on the 0-500k band and receive on the 500k to 1000k band; the other end can do the converse. This is called Frequency Division Multiplexing or FDM and is widely used in broadband networks.
Another possibility is for the nodes to take turns using the network, which is called Time Division Multiplexing or TDM. TDM methods are discussed in some detail below.
FDM is only practical in analog transmission schemes and it reduces the maximum bit rate for each node. TDM doesn't have that problem, but time-sharing often wastes valuable transmission time when nodes don't use their allocated time. Contention methods often waste time with wasted transmissions that are involved in collisions or with contention resolution algorithms that take significant amounts of time. There isn't a clear winner here, simply several possible choices.
For LAN's the situation is a little different because the desire to get lots of connections in a small space usually leads to the use of a broadcast methodology. There are several topologies:
- bus topologies, where all nodes are connected to a single medium and transmissions propogate to all parts of the network and then are absorbed. Every node hears every transmission.
- ring topologies, where all the nodes are connected to a single medium that has no end point so that a transmission goes all the way around the network and unless removed, will continue to loop. Barring errors, every node hears every transmission. This is effectively a series of point-to-point connections.
- star topologies, where there is a central device that transmits all messages to every node, but each node has its own medium. All nodes hear a message only if the central controller chooses to broadcast it to all connected nodes.
- distributed topologies, where the medium is usually the air and all stations within hearing distance hear every transmission, but quite often, there are nodes that can't hear each others transmissions.
All LAN's use some form of TDM, either taking turns or contending for use of the medium. This is primarily to maintain data rates that are as high as possible, but it also fits the general nature of computer data communications which are bursty - heavy loads for a time period and then low requirments for a time period. The various forms of TDM can be catgorized as:
- Round-robin
- Token-passing
- Contention
Round-robin methods rotate the right to transmit from one station to the next until all have had a turn and then they start the process over again. Some of the problems with round-robin are synchronizing the nodes so that two don't try to transmit at once and avoiding the lost capacity if a node has nothing to send. For the latter problem, methods have been developed that allow stations with nothing to send to forfeit their turn to the next station.
In token-passing, only the station holding the token can send data on the network, and the token passes from station to station until it reaches a station with data to send. It is similar to round-robin but has fewer synchronization problems. The major problems with token-passing involve the difficulties in managin the token which can disappear or get duplicated due to some fairly common network operations.
One last possibility is to use time division multiplexing with contention (TDM with contention). Instead of a clearly defined time period, the nodes compete or contend to get access to the channel. If a node has something to send, it signals its intentions in some way, or simply starts sending. If both attempt to use the medium at the same time, there will be a collision and some sort of collision resolution algorithm will be required to resolve the conflict. For example, if they have a separate signaling channel and they both indicate a desire to transmit, they might do some sort of electronic coin toss to decide who goes first. If multiple nodes send a message at the same time, it will be corrupted, but how do they know? Since the resulting signal is the result of adding the all the transmission signals, the nodes can tell there is something wrong by reading the medium. If the voltage is supposed to be 0-5 volts and a node sees a signal value of 9 volts, its probably because of a collision. All nodes recognize the problem and they send again after resolving which node should go first.
For beginners, the idea that several computers can share a medium seems impossible, but you know enough about data communications to know that the medium is simple a device that can be driven to represent a signal. If one transmits, all connected nodes can receive it; if more than one transmits you get a combined signal that does not have useful data in it.
Performance
Network designers are very interested in the performance of their network. It allows them to identify potential bottlenecks and to design higher-level protocols that will take full advantages of the capabilities of the underlying physical network.
The performance might be measured in terms of :
- Channel utilization
- User response time
- Throughput (Amount of data transmitted per unit time)
- Error rates
- MP3 files per day
While any of these can be used to demonstrate different capabilities, the measure that is typically used it utilization. Utilization measures the ability of the design to make use of the available capacity of the network. For example, if a network has a capacity if 1 Mbps (million bits per second) and it can transmit continuously with no overhead, the utilization is 100% - every possible bit of capacity is being used. In general, you can express utilization by either of the following relationships:
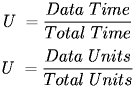
For example, if a network transmits data for 3.5 seconds out of every 4, the utilization is:
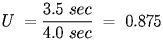
Or is a network has a capacity of 1 Mbps and it transmits an average of 500 Kbps, then the utilization is:
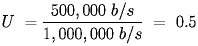
Of particular interest to us is how the access algorithms and framing choices impact the utilization. For example, suppose you decide to use FDM and you have 10 channels that can transmit at 100 Kbps for a total of 1 Mbps.
- If each of the ten nodes transmits continuously at 100 Kbps, the utilization is:
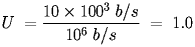
- If each node transmits continuously, but the framing information requires 100 bytes for every 1000 bytes (10% overhead), so the utilization is:
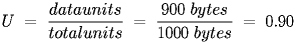
- If, on average, the nodes only transmit 40% of the time, then you would expect to find that only 400 Kbps is being transmitted at any given time. Of that 400 Kb, 10% is overhead framing, so the utilization is:
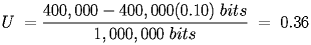
If you decided to use TDM instead of FDM, you need some form of access control that allows the nodes to take turns.
- If all 10 nodes take turns transmitting 100,000 bytes (0.01 seconds at 1 Mbps) continuously and each 100,000 bytes requires 500 bytes of framing the utilization is:
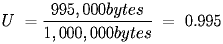
- If only 8 nodes transmit during their turn on average, you would expect that in each round, 8 nodes transmit and two do not, so the utilization is:
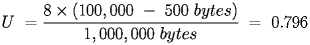
- Finally, suppose the round robin access method is changed to a token ring method where the token passing takes 1 msec and 60% of the time a node transmits an average frame of 1000 bytes with 100 bytes of framing overhead. This seems unduly complicated, but it can be broken down into a full round of sends. To pass the token between the 10 nodes takes 10 msec of token passing overhead. During the round 6 stations send 5400 bytes of data and 600 bytes of frame header. So a complete round takes the token passing time plus the sending time and the overhead is the token passing time and the framing overhead send time. The time for the token to make a circuit is:
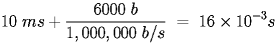
And the time to send the 600 bytes of framing overhead during the circuit is:
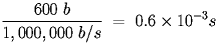
The remaing time, after removing the token passing time and the framing overhead time is the time spent sending the data. So the utilization is:
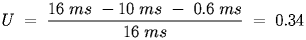
|
The conditions that affect network utilization are:
- The number of nodes.
- The demands of the nodes for capacity.
- Framing choices.
- The access algorithm.
Throughput is often important in assessing whether a particular network will provide the necessary service. It is typically measured in bits or bytes per-second. A network with a utilization of 100% has a throughput equal to the network capacity. For example, a 100 Mbps network with a utilization of 100% has a throughput of 100 Mbps. If the utilization is less, the throughput will always be U * D, where D is the number of data bits in each message.
Response time is also of interest if you want to know how long you might have to wait to send a message. This is usually determined by determining the probability of a successful send, P. The expected number of times that a station might have to try to send before suceeding is determined from the geometric distribution:
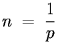
|
where n is the expected number of attempts needed to succeed. If n is multiplied by the expected time between attempts, you have the response time. For different networks, the time between attempts can be significantly different. Some physical layers have nearly fixed times between attempts while others can vary depending on the conditions. Note that if you are interested in the expected number of failures instead of the number of attempts, simply subtract 1 from one from the expression above.
Generalizing Performance
Suppose we have a perfect MAC layer protocol, which means that the channel is as full as can be obtained and that messages contain no overhead information.
- R is the channel data rate in bits per second.
- V is the propogation rate of the signal.
- D is the maximum distance between nodes.
- L is the frame length in bits, average or fixed.
- T is the expected time required to transmit a frame.
- t is the expected propogation time of a bit.
- The first bit of a messages takes t= D/V seconds.
- A message takes T = L/R seconds to transmit.
- The ratio of propogation delay to frame transmit time is, a = (D/V)/(L/R) = RD/LV. This is a measure of the proportion of the time that is actually used to transmit message bits, rather than waiting for them to travel.
For a perfect MAC layer protocol, the frame is all data and all stations send, so the only cost is the time consumed in propogating the bits of a frame across the channel. Let V be 2 x 10^8 m/s for a constrained medium (rather than the 3 x 108 m/s for free-space propogation.
-
U = throughput/capacity = (L/R)/(L/R + D/V)
= 1/(1 + RD/VL) = 1/(1+a)
Now what good is this you might ask? If we plug in different data rates (D), frame lengths (L) and network lengths (D), we will see what effect these parameters have on network utilization.
| Data | Frame | Network | ||||||
|---|---|---|---|---|---|---|---|---|
| Rate | Length | Size | a | U | ||||
| 1 Mbps | 100 bits | 1 km | 0.05 | 0.95 | ||||
| 1 | 1000 | 1 km | 0.005 | 0.99 | ||||
| 10 | 100 | 1 km | 0.50 | 0.67 | ||||
| 10 | 1000 | 1 km | 0.05 | 0.95 | ||||
| 10 | 1000 | 10 km | 0.50 | 0.67 | ||||
| 100 | 1000 | 10 km | 5.00 | 0.17 | ||||
| 100 | 10000 | 10 km | 0.50 | 0.67 | ||||
| 100 | 10000 | 50 km | 2.50 | 0.35 |
As you can see, higher data rates actually reduce the utilization because the propogation rate is the same, and so a greater percentage of the time is wasted. Likewise, longer media length reduce utilization and longer frame lengths increase utilization.
This is only for a perfect MAC layer protocol. What if we include something about the access algorithm? Assume that we have a round-robin protocol:
- N is the number of nodes on the network.
- k is the expected number of nodes that transmit in a round.
In any given round, you would expect the transmit k messages, and have N-k slots which are unused. Assuming the slots are exactly the length of the messages:
-
throughput = k * (L/R)
and the capacity is:
-
capacity = N * (L/R + D/V)
So:
-
U = throughput / capacity = [k * (L/R)]/[ N * (L/R + D/V)]
= k/N * 1/(1+a)
So the ideal utilization is multiplied by the factor k/N, which can have a maximum of 1. The utilization diminishes linearly with the number of stations sending on average.