Introduction
A software protocol is simply a methodology or discipline for communicating across a channel. In the physical layer discussions, you were introduced to several protocols (IEEE 802.3, 802.5, 802.11b for example), each of which has different methods for accessing the network and communicating data. Software protocols also come in a wide variety of types, but typically share several important properties.With software protocols, we are typically interested only in point-to-point communication between two entities on the network, usually two programs. Also, we are interested in communication over channels, not physical lines. If you recall, a channel is a virtual communication entity, that might be composed on any combination of physical layers methods. For example if you use a browser to access a web server at some other location, you aren't interested in what physical layers are involved or how your messages are handled, only in the results. The channel is a simple way of discussing this higher layer of communication that can be treated as a simple pipeline for data.
Our terminology is also extended here with the term packet, which simply means one communication unit. In the physical layer, these are typically called frames. A packet is simply one grouping of information, typically including some sort of data and the framing information needed to make the protocol work properly.
Properties of Software Protocols
Protocols can be differentiated from each other on the basis of the following properties:
- Connectionality
- Reliability
- Flow control
- Directionality
- Addressing
Connectionality
Connectionality is concerned with how the two endpoints of the communication handle their relationship. Do they begin by making a connection agreement that allows them to establish the parameters of the communication to follow, or do they simply send data without any prior arrangement? The first method, called connection-oriented, is similar to a traditional telephone call, where the originator starts by dialing the number and waiting for a connection to be made when the receiver accepts the call. Along the way, the resources for the call are allocated and both end points have an agreed upon methodology (although with people its hard to tell and constantly changing). Connectionless is more like traditional mail service, where you simply address an envelope and drop it in the mailbox to be delivered at the other end without prior arrangement. In the physical layer world, the SONET protocol is a connection-oriented protocol, while IEEE 802.3 is connectionless.
Reliability
Reliability is a measure of how well the protocol manages errors that might occur. Remember that a channel may well cross a large and complex subnetwork with many nodes and physical links, and bad things can happen to good packets. The things that can happen are:
- Data errors caused by some sort of device or communication problem
- Lost packets which are the result of some node not forwarding a packet due to congestion in the network, a node error, or possible an unrecoverable data error.
- Duplicate packets, which can occur if a packet seems to be lost and is sent again, only to find out that the original wasn't lost after all.
- Out-of-order packets which can be the result of a sequence of packets taking different routes to the destination and later packets finding a shorter route.
While protocols can handle some subset of these, the general terminology is that a protocol that addresses all of them is reliable, while a protocol that addresses none or some is called unreliable.
Flow Control
Flow control refers to the methods used by the protocol to prevent data from arriving too fast for the system to handle it. For example, if you have a slow machine on one end and a fast machine on the other of a connection, the fast machine could fill up all the buffer space on the slow machine and eventually crash it. To prevent this, some protocols implement flow control methods to restrict traffic. While there are degrees of flow control, it is generally correct to assume that connection-oriented protocols implement flow control and connectionless do not. It is of interest to protocol designers to see the different methods used.Directionality
Protocols are either simplex, allowing data to flow in only one direction or duplex, allowing data to flow in both directions. We are typically interested in duplex protocols but in most cases, we can treat a duplex protocol as a simplex protocol operating in each direction.Addressing
Some protocols don't require any addressing because there is one and only one possible destination when a packet is sent. For others, addresses are a major concern because they have responsibilites such as routing or multiplexing several communication channels. If addressing is important, the issues are the kind of address to use and how to integrate it into the operation of the protocol.Simplex Unreliable Protocol
The simplest protocol of all is one where one end transmits data to the other end with not data returning in the other direction and with no concern about errors. The channel is like a mail chute where one end can drop letters that are removed at the other end and processed. If anything goes wrong along the way, the sender doesn't know or care (at least not immediately), the directionality is simplex, the connectionality is connectionless and there is no flow control (unless the entire system breaks down). So aside from catastrophic failure, the sender keeps sending and the receiver keeps receiving endlessly. In the real world, such protocols are common, but mostly in embedded systems and other small, tightly controlled environments.Utilization
One way to evaluate the effectiveness of a protocol is to calculate the utilization of the channel that is allocated. While no knowledge of the underlying physical channels is typically known, it is reasonable to consider the logical channel. In the case of the Unreliable Simplex Protocol, each message could consist strictly of data. If the sender could send continuously, the utilizaton would be 1.0 or 100%. However, the sender often takes some time to assemble the packets to send. This is called the send latency. If it takes 0.25 seconds to transmit a packet and 0.10 s to process the packet at each end, the utilization is:If the sender didn't have enough to send to keep the channel busy, it might be given that the sender sends a packet every 2 seconds. Then we would have a 2 s delay, then a 0.1 s delay and then a 0.25 s send, so:
Finally, suppose the sender has to add some framing information. This wouldn't be synchronization bits or CRC's typically, but could include other forms of error control, addressing or processing information for the receiver. If that information took 0.05 s of the 0.25 second send time, we have:
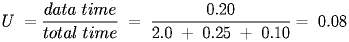{kind=link}
The basics of utilization for software protocols are similar to those for physical layer protocols; what part of a given unit of time is spent doing useful work?
Stop and Wait Protocols
A Stop and Wait protocol adds one thing to the Simplex Protocol, an acknowledgement. These protocols are duplex, rather than simplex and information can move in both directions. At this point in time we don't care about reliability or connectionality. We will assume that one side is sending data and the other is receiving data. The sender sends a packet; when the receiver gets the incoming packet and checks it for errors, it sends an acknowledgement or ACK that tells the sender it is OK to send again. Clearly you could add some reliability to this protocol by sending a NAK if the message had errors in it; also there is some implicit flow control since the sender has to wait for a response before sending again.There are some sticky issues in this protocol. For example, what if a packet is lost and doesn't arrive at the receiver? How long does the sender wait for a response from the receiver? Or what if the message is received but the acknowledgement is lost? We will take these questions up later, but for now, consider the utilization properties of this protocol.
In general, if we let:
- L = Message length
- B = Data bytes in a message, so L-B bytes are overhead,
- D = the network latency, which can include propogation delay, routing time through the subnet and processing time on each end.
- R is the bit or byte rate at which data is sent.
Then the utilization is:
For example, suppose that we have a stop and wait protocol that has a message length of 1000 bytes with 20 bytes of framing, a send rate of 80,000 bits per second and propogation delay of 0.10 s and processing time on each end of 0.01 s. Since this is a stop and wait protocol, the message cycle starts when the message is sent and ends when the ACK is received. It takes two times the propogation delay, plus 4 times the processing time to get both parts of the exchange complete, so D is:
The network latency can be viewed as a time (0.24 s) or as the number of bytes (2400) that can be sent in that time. Then the utilization is:
In most cases, D is a given, rather than something that has to be calculated, and it is typically given in terms of a statistical distribution. For example, the network latency is normally distributed with a mean of 300 ms and a variance of 200 ms.
Automatic Request Protocols (ARQ)
One of the important issues raised in the stop and wait protocol discussion is related to how long the protocol should wait for acknowledgements that may not ever arrive. The sending side could have a timer that expires after a length of time and then it could take some action, but what should it be? If it sends another packet and it turns out that the first one arrived also, you would have duplicated data. But if it doesn't send anything, the protocol is irretrievably broken. One solution is to put an identifier in each packet. In the case of a stop and wait protocol, you would only need a zero or one. The first packet has a zero identifier, which is commonly called a sequence number, and the next has a one. If two successive packets have the same sequence number, the second must be a duplicate, so the receiver can send an acknowledgement and throw the duplicate away.This method of automatically resending unacknowledged packets solves two problems. Lost packets will be resent and if the receiver gets a packet with a data error, it simply waits for the resend. You could use a NAK from the receiver to indicate an error, but that has its own set of problems.
So now we have a basic protocol for each end:
Sender
- Send a packet with sequence number 0
- Set the acknowledgement timer
- If the timer expires, go to 1.
- If the acknowledgement for 0 arrives, stop the timer
- Send a packet with the sequence number 1
- Set the acknowledgement timer
- If the timer expires, go to 5.
- If the acknowledgement for 1 arrives, stop the timer
- Go to 1.
Receiver
- Receive packet.
- If the sequence number is 0, send an ACK and process it, otherwise throw it away and go to 1.
- Receive a packet.
- If the sequence number is 1, send an ACK and process it, otherwise throw it away and go to 3.
- Go to 1.
The term Automatic Request for this protocol indicates that the protocol automatically resends any packet that is not acknowledged.
ARQ protocols are typically connection-oriented due to the need to synchronize the sequence numbers and usually they are full duplex, with a sender and a receiver at each end and they can handle most of the reliability issues. They have a very strict flow control policy, since only one message at a time can be in the channel and we will take up that problem in the next unit.
Utilization for an ARQ protocol is similar to that for a stop and wait protocol, except that you must consider the possible expiration of the timer and the associated consequences. If we assume that we have some statistical information about packet loss we can estimate the likelihood that the timer expires and that we incur the cost of the timeout and retransmit. Using the notation from above, add: T, the timeout value and E, the probability of a packet loss in any exchange. This could be a packet corruption or a packet that simply doesn't arrive. Given T, we can estimate an additional cost for each packet that is the loss associated with resending a packet, plus the cost of waiting for the timer to expire. For example,
is the expected time lost for every packet sent (the probability of an error times the time to process the error). In the most complex sense, we would also have to consider that a resent packet could get an error, but we will ignore that problem. So now we have:
or using time instead of bytes:
For example, suppose that we have an ARQ network with a data rate (R) of 1 Mbps, a latency (D) of 0.01 s, a message length (L) of 1100 bytes, a header length (H) of 100 bytes, a timeout value of 0.20 s and an error rate of 0.05. So,
then
As you can see by the denominator, the latency and error cost dominate the actual cost of sending and drive the utilization to a very low value. This low utilization is a problem with an ARQ protocol of this form, so we need to find something better.