
In order for a top down parse to run in linear time, we will need to be able to ensure that at each step when we are about to expand a nonterminal,
That is, we actually would like to have a table which, given the current nonterminal to expand and the current lookahead string tells exactly which rule to use in expanding the nonterminal. Such a table would look like
| Lookahead1 | Lookahead2 | . . . | Lookaheadm | |
| Nonterminal1 | ||||
| Nonterminal2 | i | j | ||
| . . . | ||||
| Nonterminaln |
Note the following about this table:
The nonterminals are listed as the row headings.
The lookahead strings are listed as the column headings.
An entry in the table tells which rule to apply. For example, the table indicates that if one is to expand Nonterminal2 next in the tree and the current lookahead string is Lookahead2 then apply rule j.
Blank entries in the table indicate errors; there is no rule to apply in such cases, so there must be an error in the input token string.
If any entry has two or more rules in it, the grammar is not LL(k). Two or more entries just mean that when one is about to expand the nonterminal that labels the row, the given lookahead string is not sufficient to determine which of the different rules to apply.
This will become clearer later. For now, let's try to do a top down parse using the following grammar and one token of lookahead.
We will once again use Grammar 3 to do a parsing example, similar to the example done in the previous lecture. You should read this example carefully if you have any concerns about how parsing proceeds.
1. <expression> --> <term> <expression_tail> 2. <expression_tail> --> + <term> <expression_tail> 3. <expression_tail> --> - <term> <expression_tail> 4. <expression_tail> --> lambda 5. <term> --> <factor> <term_tail> 6. <term_tail> --> * <factor> <term_tail>> 7. <term_tail> --> / <factor> <term_tail> 8. <term_tail> --> lambda 9. <factor> --> <primary> <factor_tail> 10. <factor_tail> --> ^ <primary> <factor_tail> 11. <factor_tail> --> lambda 12. <primary> --> identifier 13. <primary> --> integer_literal 14. <primary> --> ( <expression> )
This grammar is Grammar 3 of a few lectures ago. We have just numbered the rules here for reference. In order to do a parse in a real programming language we usually add one new rule that normally does not show up in the grammar for the language. The rule is something akin to
0. <system_goal> --> <expression> eof
The idea is that we create a new start symbol, in this cases called <system_goal> and then add one new rule that can be used to replace <system_goal> with the old start symbol (in this case <expression>) followed by the end of file token. This allows the parse to quit when the end of file token is encountered. We add this kind of rule to all of the grammars we use for parsing programming languages.
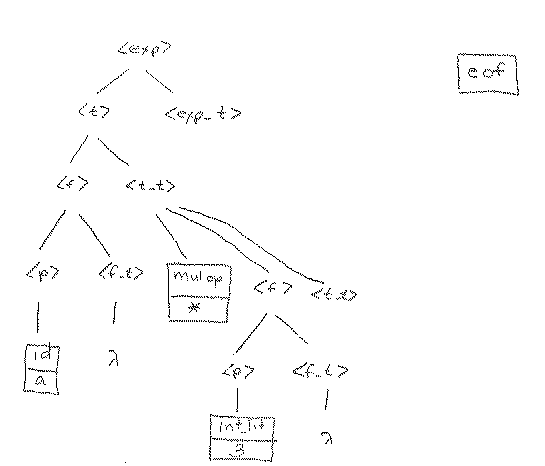
Let's do a top down parse of some string using one token of lookahead (we will shorten the nonterminal names to make the tree easier to draw). We must start with <exp> as our start symbol. Suppose that the first lookahead token is an identifier (id). As humans, we wish we could see more than just the first token, but, alas, that is not to be. We must decide which rule to apply given just this one token of lookahead. (In the parse tree, we will use shortened names for the nonterminals and terminals to make the tree manageable.) (Note: in the future, these diagrams would need to be modified so that the root of the tree is <system_goal> rather than <expression>). So, the status of our parse tree is:
Actually, it might appear that we are in luck. There is only one rule to apply (rule number 1). However, we only want to apply this rule if it really makes sense to do so with a lookahead of id. We see that it does, because rule 1 leads to <term> first, then <term> leads to <factor> first in rule 5, then <factor> leads to <primary> first in rule 9, and <primary> can produce an identifier in rule 12. So, applying rule 1 to the tree above makes sense.
To see what "makes sense" means, consider the case where the lookahead token is a + instead of an id. There is no way that <exp> could ever lead to a + as the first token produced, so it wouldn't make sense to apply rule 1 in that case, even though rule 1 is the only rule that can be used. We would know already that there is a syntax error in the program.
Let's apply rule 1.
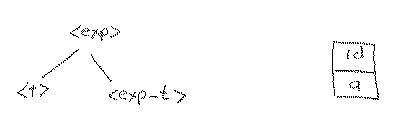
Now, we need to expand <t> next. Since the lookahead token id has not yet been attached to the tree, it remains our lookahead token (we are still looking ahead to it). Is there a rule we can apply to <t> that makes sense with the id as our lookahead token? That is, could we ever produce an id as the first token starting with <t> and applying rules? Again the answer is yes, with a similar argument as above. The rule to apply is rule 5.
Let's apply rule 5.
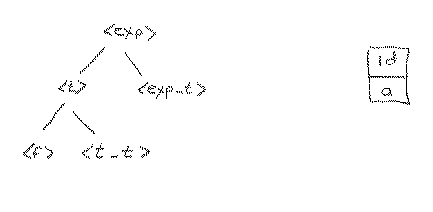
After applying rule 5 above, we still have id as our lookahead, because it has not yet been attached to the tree. We must now expand <f>. An argument similar to the one above tells us that in this case we should apply rule 9, which gives us the tree below.
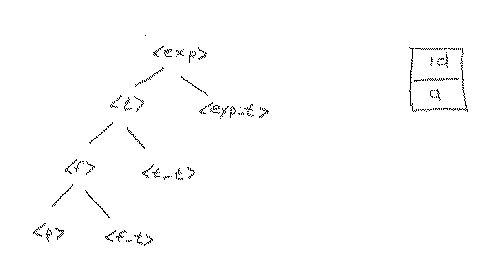
Now, we must expand <p>. Since the lookahead is an id, it is clear that the only way to expand <p> is to use rule 12, because that leads to the id that has been our lookahead until now. That is, we can now attach the id from the token file to the tree and get the next token in the token file to use as our lookahead. If we applied rule 13, we would attach an int_lit to the tree, which doesn't match the input and therefore would be wrong. Similarly, if we applied rule 14 we would attach a l_paren to the tree at this point, which would also be incorrect. The correct expansion, along with the acquisition of the next token for our lookahead is shown below.
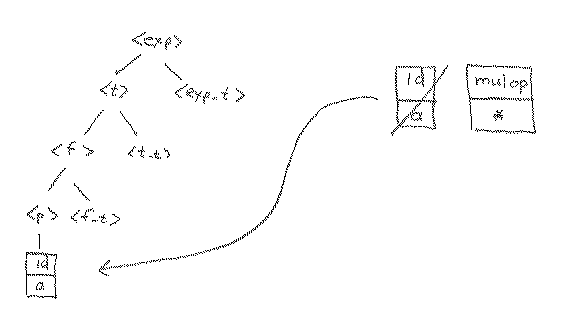
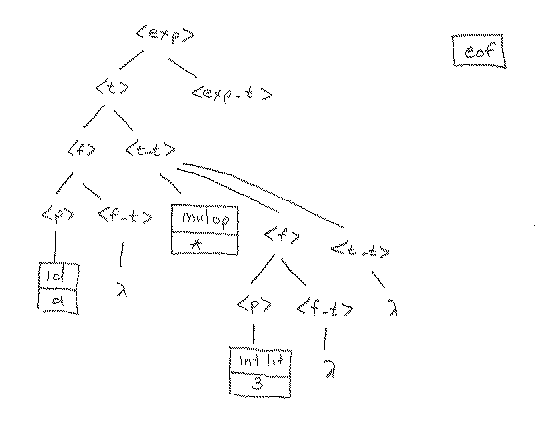
At this point, we finally get to look at the next token in the token file, and we find that it is a mul_op. We have to expand nonterminal <f_t> at this point. But we see that <f_t> can never lead to a mul_op as the first token produced. We could, therefore, just apply rule 11, the lambda rule, but we should only do that if we know that a mul_op really can appear at this point. Sure enough, looking at the tree, we see that it could come from <t_t>, so we go ahead and apply rule 11 at this point.
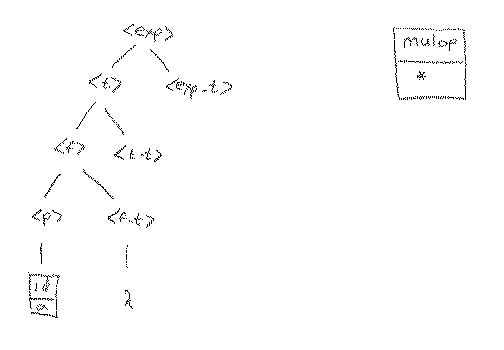
With the lookahead of 3 at this point, where we need to expand <t_t> we see immediately that rule 6 at this point. This attaches the * to the tree, which means that we get to ask for a new lookahead token. In this case we get an integer literal (3) as the next lookahead.
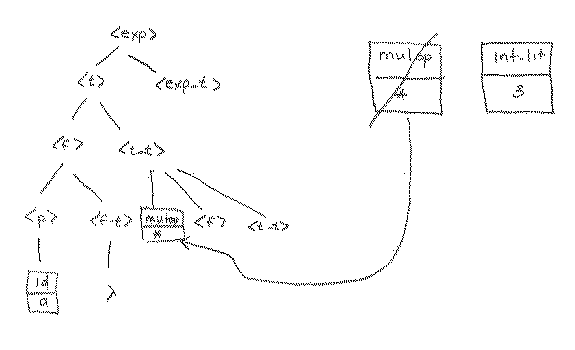
Using the same arguments as before, we now complete the tree. In this case, for example, we can get to an integer literal from <f>, so we apply the rule that would start in that direction (rule 9).
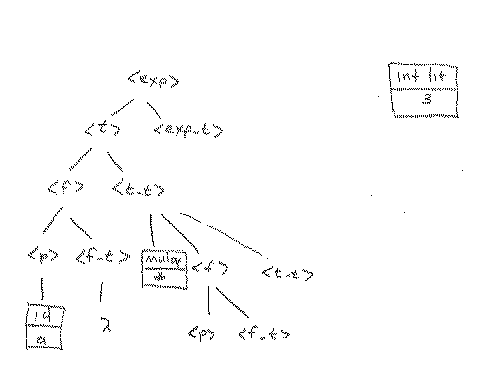
At this point, then, we expand <p> directly, attaching the integer literal 3 (via rule 13) to the tree, and then get the next lookahead, which is eof.
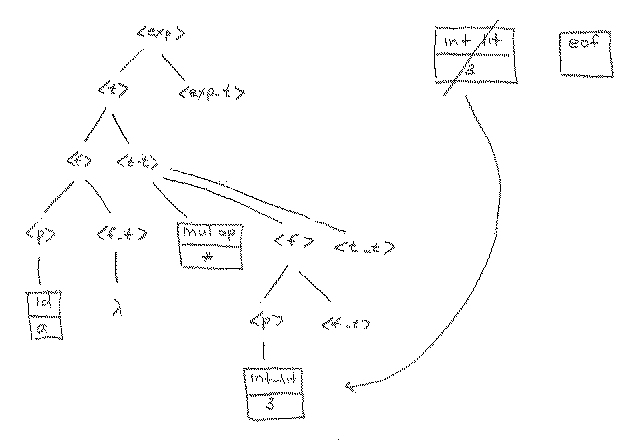
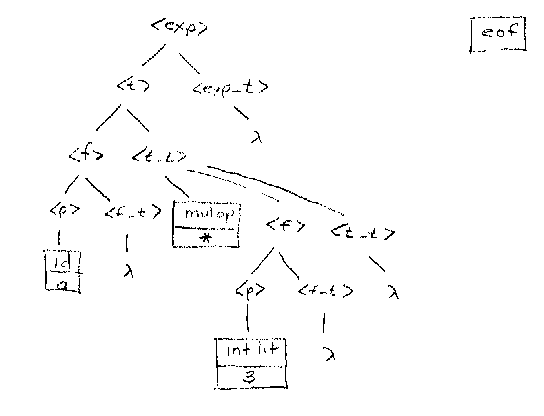
The lookahead of eof means that we are at the end of the string. By examining the grammar, we see that we can indeed expect to see an eof when we expand <f_t>, because there may be no more factor tails, term tails or expression tails (the input expression may be finished). So, the next three operations show that l rules are applied to <f_t>, <t_t> and <exp_t> in successions, showing that there is a parse tree for the input string
a * 3
The interesting and important thing is that we were able to construct this parse tree without looking at the entire string or even knowing what it was. Instead we did it by looking at just one token at a time.
If we think about the parse tree we expanded last time, we may find that there are some efficiencies we can apply. For example, if we are doing top-down parsing with no backtracking, then we really don't need to keep the entire tree around to determine how to proceed with the parse. Once we have expanded a nonterminal, we never go back to look at that nonterminal. Therefore, we just need to keep track of the parts of the tree that remain to be processed.
One way to understand this is to remember that we never did look at any of the ancestors in the tree of the node we were about to expand in determining how we should expand this current node. Some points to note for compiling are these:
An example of parsing without keeping the entire tree around is given below. We use Grammar 3 again, and again we parse a*3. Compare this method with the example above in which the entire tree was kept:
0. <system_goal> --> <expression> eof 1. <expression> --> <term> <expression_tail> 2. <expression_tail> --> + <term> <expression_tail> 3. <expression_tail> --> - <term> <expression_tail> 4. <expression_tail> --> lambda 5. <term> --> <factor> <term_tail> 6. <term_tail> --> * <factor> <term_tail>> 7. <term_tail> --> / <factor> <term_tail> 8. <term_tail> --> lambda 9. <factor> --> <primary> <factor_tail> 10. <factor_tail> --> ^ <primary> <factor_tail> 11. <factor_tail> --> lambda 12. <primary> --> identifier 13. <primary> --> integer_literal 14. <primary> --> ( <expression> )
Note the following:
Let's try it. First we start with the start symbol of the grammar and use the first lookahead token to decide how to expand the start symbol.
Unprocessed Leaves Lookahead Token<system_goal> id, a
As before, the lookahead token lets us know that it is ok to apply rule 0, which gives
Unprocessed Leaves Lookahead Token Rule<expression> eof id, a 0
This in turn tells us to use rule 1, <expression> --> <term> <expression_tail>. This time when we apply this rule, though, we simply replace <expression> with its right hand side, yielding
Unprocessed Leaves Lookahead Token Rule<term> <expression_tail> eof id, a 1
We still have the same lookahead symbol (id a). We need to expand <term> at this point (the leftmost nonterminal). The lookahead predicts that we should apply rule 5. So we replace <term> with the right hand side of rule 5.
Unprocessed Leaves Lookahead Token Rule<factor> <term_tail> <expression_tail> eof id, a 5
Proceeding on, we now need to expand <factor> using the lookahead token, giving
Unprocessed Leaves Lookahead Token Rule<primary> <factor_tail> <term_tail> <expression_tail> eof id, a 9
The next step is to expand <primary>, giving
Unprocessed Leaves Lookahead Token Ruleidentifier <factor_tail> <term_tail> <expression_tail> eof id, a 12
Since token identifier matches the lookahead token, we can now eliminate it from the tree and obtain the next lookahead token, getting
Unprocessed Leaves Lookahead Token Match<factor_tail> <term_tail> <expression_tail> eof mulop, *
Again, here, we expand <factor_tail> using the lookahead tokent to get
Unprocessed Leaves Lookahead Token Rule
<term_tail> <expression_tail> eof mulop, * 11
This leads us to expand <term_tail> with the mulop lookahead token to get
Unprocessed Leaves Lookahead Token Rule* <factor> <term_tail> <expression_tail> eof mulop, * 6
At this point, since the * in the expansion matches the lookahead token, we can eliminate it from the expansion and obtain the next lookahead token:
Unprocessed Leaves Lookahead Token Match<factor> <term_tail> <expression_tail> eof int_lit 3
This in turn forces the next expansion to be
Unprocessed Leaves Lookahead Token Rule<primary> <factor_tail> <term_tail> <expression_tail> eof int_lit 3 9
And then
Unprocessed Leaves Lookahead Token Rule3 <factor_tail> <term_tail> <expression_tail> eof int_lit 3 13
Again, since the 3 in the expansion matches the lookahead token, we eliminate it from the expansion and get the next lookahead.
Unprocessed Leaves Lookahead Token Match<factor_tail> <term_tail> <expression_tail> eof eof
As in our parse tree example from last time, the eof lookahead token will cause all three of the remaining nonterminals in the expansion to be reduced to l by the appropriate rules. Use of an l rule just erases the nonterminal from the expansion. So the next three rule applications lead in succession to the following three expansions.
Unprocessed Leaves Lookahead Token Rule<term_tail> <expression_tail> eof eof 11
Unprocessed Leaves Lookahead Token Rule<expression_tail> eof eof 8
Unprocessed Leaves Lookahead Token Ruleeof eof 4Unprocessed Leaves Lookahead Token Match
At this point, the parse is finished. The fact that there are no more unprocessed leaves and we have a lookahead token of eof tells us that the parse was successful. In this case this just means that the string
a * 3
is a valid string in the language of this grammar.
Since we don't need to keep the entire tree around, we can write a recursive descent parser that uses one token of lookahead in the following manner.
For each nonterminal we have a procedure.
Such a procedure is to be called only when the nonterminal that names that procedure is the one to be expanded in our leftmost parse.
The procedure a case statement that selects the correct rule to expand from among all of the rules with that nonterminal on the left based on the current lookahead symbol (that is, the lookahead symbol triggers the switch).
The selected rule is expanded by dealing with each token and nonterminal on the right hand side of that rule individually. Nonterminals are processed by simply calling the procedure for that nonterminal (so that it can expand), and tokens are processed by simply matching them with the input token file to ensure that they show up in the correct spot. When a match of a token is made, that is the same as processing it in the expansion, so the routine that does the match must also get the next lookahead token.
There must be an "others" part to the case statement in case no rule applies. That is, if the lookahead token that triggers the case switch does not predict that any rule applies, there must be an error in the program. This will be handled in the "others" clause.
Using our example grammar, the procedure for nontermintal <term_tail> must therefore have a form similar to
procedure term_tail isbegin case Lookahead is -- Lookahead is a global variable when dummy1 ==> -- <term_tail> --> * <factor> <term_tail> Match('*'); Factor; Term_Tail; when dummy2 ==> -- <term_tail> --> / <factor> <term_tail> Match('/'); Factor; Term_Tail; when dummy3 ==> -- <term_tail> --> lambda null; when others ==> Error; end case; end term_tail;
Notice that we don't know which tokens predict which rules yet, so we just put dummy case selectors in at this point. Every nonterminal will have a procedure like this.
We can figure out some of the predicting lookaheads, to get
procedure term_tail is
begin
case Lookahead is -- Lookahead is a global variable
when '*' ==> -- <term_tail> --> * <factor> <term_tail>
Match('*');
Factor;
Term_Tail;
when '/' ==> -- <term_tail> --> / <factor> <term_tail>
Match('/');
Factor;
Term_Tail;
when +, -, ), eof ==> -- <term_tail> --> lambda
null;
when others ==>
Error;
end case;
end term_tail;
The lookaheads that trigger the last rule are more problematic, because they can only be determined by a careful analysis of the grammar.