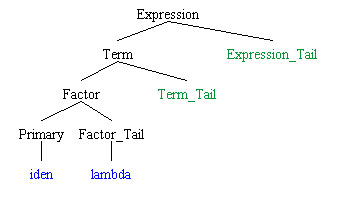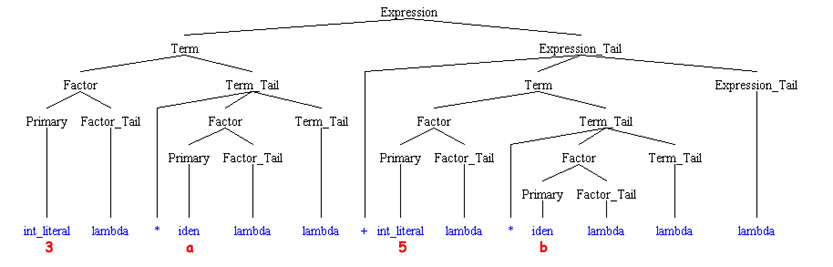
The parsing method discussed here does not require that the parse tree be kept around. Note, though, that the parse tree can be reconstructed directly if we keep
Many parsing strategies require that tree information be kept around for the duration of the compile. Use can often be made of these trees to produce more efficient target code. However, there are a lot of rules in most grammars that are necessary for ensuring that a string has the proper form (syntax) that can be discarded once that determination has been made. This can result in more compact "abstract syntax trees" that can be used as the intermediate output of the compiler. For example, the expression
3*a + 5*b
has the following tree according to grammar 3.
This is one big ugly tree for a relatively small expression. It was necessary to build this tree in order to ensure that the expression met the rules of the grammar. However, once built, the important information in the tree can be distilled to:
+
/ \
/ \
/ \
* *
/ \ / \
/ \ / \
3 a 5 b
This tree gives in concise form the order of the operations and the operands. In other words,
it abstracts the essential syntactical information from the parse tree above, which is why it is
called an abstract syntax tree.
Our purpose at this point is to learn how to write the procedures for a recursive descent parser. Given a context free grammar for the programming language we are trying to parse, we write a procedure for each nonterminal. For example, from the lecture last time, we gave the following outline for the procedure term_tail (based on the grammar labeled grammar 3).
procedure term_tail isbegin case Lookahead is -- Lookahead is a global variable when ?? ==> -- <term_tail> --> * <factor> <term_tail> Match('*'); Factor; Term_Tail; when ?? ==> -- <term_tail> --> / <factor> <term_tail> Match('/'); Factor; Term_Tail; when ?? ==> -- <term_tail> --> lambda null; when others ==> Error; end case; end term_tail;
Every procedure will have this form.
In other words, when procedure term_tail is called as in this example, this corresponds to the situation in the parse tree which we can illustrate generically as
In this illustration we see that it is time to expand term_tail in this top-down, leftmost parse. In following the LL(1) approach, we must be able to decide which rule to apply to term_tail given the next lookahead token. In fact, this next token should even be able to indicate if no rule applies, and that there is therefore a parse error.
Look back up at the procedure for term_tail now. From what we gather from the tree, we can see that in the procedure for term_tail we must fill in the ??'s with the lookahead tokens that predict that the rule of that when clause should be used to expand term_tail. We do this by constructing an LL(1) table. This table, recall, has the form
| Token 1 | Token 2 | . . . | Token m | |
| Nonterminal 1 | ||||
| Nonterminal 2 | ||||
| . . . | ||||
| Nonterminal n |
The nonterminals of the grammar are listed as the row headings and the tokens are listed as the column headings. The entries are rule numbers which indicate which rule to use to expand the nonterminal on the row heading when the lookahead is the token of the column heading. Once we have this table, we can easily fill in the when clauses of the nonterminal procedures in our recursive descent parser.
Let's give this a try. Let's use the following grammar this time.
1. <start> --> <expression> eof 2. <expression> --> <expression> + <term> 3. <expression> --> <expression> - <term> 4. <expression> --> <term> 5. <term> --> <term> * <factor> 6. <term> --> <term> / <factor> 7. <term> --> <factor> 8. <factor> --> <factor> ^ <primary> 9. <factor> --> <primary> 10. <primary> --> identifier 11. <primary> --> integer_literal 12. <primary> --> ( <expression> )
For this grammar we have the following table structure.
| eof | + | - | * | / | ^ | id | int_lit | ( | ) | |
| <start> | ||||||||||
| <expression> | ||||||||||
| <term> | ||||||||||
| <factor> | ||||||||||
| <primary> |
Let's try to fill in the table entris for row <expression>. There are three rules in this grammar with <expression> on the left, rules 2, 3, and 4. Thus, we would expect to find rules 2, 3, and 4 in this row. This is because the row for <expression> is to provide information about which rules apply for expanding <expression> in a parse given the next lookahead symbol. It wouldn't make any sense to have, say, rule 9 listed in this row, because rule 9 applies to nontermina <factor>, not nonterminal <expression>.
To decide which tokens predict that we should use rule 2, we have to see where that rule would lead. That is, we have to look at the right hand side of rule 2,
<expression> + <term>
and see where this would lead. That is, we need to apply an algorithm, which we call First to this right hand side, and First should give us the set of tokens that could appear in the first position from expanding this right hand side.
We thus look at where <expression> (the first nonterminal on the right hand side) can take us. We notice, among other things, that it can be expanded to give a <term> in the first position, which can be expanded to give a <factor> in the first position, which can be expanded to give a <primary>. The three rules with <primary> on the left produce three different tokens in the first position, namely, identifier, integer_literal, and the left parenthesis, (. If we examine the grammar carefully, we see that these are the only tokens that can appear in the first position if we apply rule 2. Thus, we have:
First(<expression> + <term>) = { identifier, integer_literal, ( }
What this means is that if we are ever about to expand <expression> in a top-down, leftmost parse, the three lookahead tokens, identifier, integer_literal, and (, each predict that we can use rule 2, because rule 2 will lead to this token. It also means that any other lookahead, such as * can never be reached as the first token if we use rule 2, so there must be an error in the string we are parsing. Therefore, we can insert rule 2 into the table in the following positions.
| eof | + | - | * | / | ^ | identifier | integer_literal | ( | ) | |
| <start> | ||||||||||
| <expression> | 2 | 2 | 2 | |||||||
| <term> | ||||||||||
| <factor> | ||||||||||
| <primary> |
We continue filling out row <expression> of the table this way. To decide which tokens predict using rule 3, we must compute
First(<expression> - <term>)
Following the same argument as above, we find out:
First(<expression> - <term>) = { identifier, integer_literal, ( }
Which is the same set as before. In fact, for rule 4, we get the same thing, by the same argument:
First(<term>) = { identifier, integer_literal, ( }
This gives us the following table entries so far
.
| eof | + | - | * | / | ^ | identifier | integer_literal | ( | ) | |
| <start> | ||||||||||
| <expression> | 2, 3, 4 | 2, 3, 4 | 2, 3, 4 | |||||||
| <term> | ||||||||||
| <factor> | ||||||||||
| <primary> |
The fact that there are multiple numbers in these entries lets us know that there is a problem. If we are doing a top-down, leftmost parse with this grammar, and if we are about to expand <expression>, then a lookahead of identifier tells us that rules 2, 3, and 4 could all be applied, because they all could lead to this identifier first. This is called a conflict, because we are stuck. We don't know which rule to apply. Therefore, this grammar is not LL(1) and cannot be used as it is for a recursive descent parser based on a single lookahead token.
If we were to continue to fill out this table for this grammar, we would find all kinds of conflicts. Even for real programming languages with grammars carefully constructed to avoid such conflicts, we will occasionally have conflicts. If there are only a few, we can continue with our recursive descent strategy and handle the few conflicts as a special case, as we will see later.
Instead, though, let's look at the following grammar that generates the same language as the first grammar. We have seen this grammar before. We have said that it is LL(1). If this is true, the LL(1) table we build for it should have no conflicts in it. Let's try.
1. <start> --> <expression> eof 2. <expression> --> <term> <expression_tail> 3. <expression_tail> --> + <term> <expression_tail> 4. <expression_tail> --> - <term> <expression_tail> 5. <expression_tail> --> lambda 6. <term> --> <factor> <term_tail> 7. <term_tail> --> * <factor> <term_tail>> 8. <term_tail> --> / <factor> <term_tail> 9. <term_tail> --> lambda 10. <factor> --> <primary> <factor_tail> 11. <factor_tail> --> ^ <primary> <factor_tail> 12. <factor_tail> --> lambda 13. <primary> --> identifier 14. <primary> --> integer_literal 15. <primary> --> ( <expression> )
Our table will start out looking like this:
| eof | + | - | * | / | ^ | identifier | integer_literal | ( | ) | |
| <start> | ||||||||||
| <expression> | ||||||||||
| <expression_tail> | ||||||||||
| <term> | ||||||||||
| <term_tail> | ||||||||||
| <factor> | ||||||||||
| <factor_tail> | ||||||||||
| <primary> |
Let's try filling in the table for row <expression_tail>. To see which tokens predict that we should use rule 3 for expansion, we must compute First of the right hand side of rule three, as before. This one is easy.
First(+ <term> <expression_tail>) = { + }
The only token that application of rule 3 can lead to first is +, because rule three immediately produces the token + as its first symbol. That is, if we are doing a top-down, leftmost parse, and we are about to expand <expression_tail>, then the only lookahead token that will predict that we should use rule 3 is +. This means that we can put a 3 in row <expression_tail> column + of our LL()1) table.
The computation of the first set for rule 4 is similarly easy. It is
First(- <term> <expression_tail>) = { - }
This means that we can put a 4 in row <expression_tail> column - of our LL(1) table, which gives
| eof | + | - | * | / | ^ | identifier | integer_literal | ( | ) | |
| <start> | ||||||||||
| <expression> | ||||||||||
| <expression_tail> | 3 | 4 | ||||||||
| <term> | ||||||||||
| <term_tail> | ||||||||||
| <factor> | ||||||||||
| <factor_tail> | ||||||||||
| <primary> |
Now we get to the rule 5, the last rule with <expression_tail> on the left. This is the last rule we must process in order to complete row <expression_tail> of the LL(1) table for this grammar. This rule is different, because it has the empty string on the right:
5. <expression_tail> --> lambda
This means that we must compute First(lambda). This gives us
First(lambda) = {lambda}
However, the empty string is not a token. Our scanner will never return the empty string as the lookahead token. Again, think of a top-down, leftmost parse tree. We are in the situation of trying to expand <expression_tail>. If the lookahead is a +, we know that we apply rule 3 from our table. If the lookahead is a -, we know that we apply rule 4 from the table. What if the lookahead is something else? Well, it couldn't come from <expression_tail>, because <expression_tail> will eventually lead to a +, -, or the empty string first. However it might come from something that follows <expression_tail>. Thus, to finish filling out this table,we need to see what could follow <expression tail> in this grammar. That is, we need an algorithm, called Follow, that will compute all of the tokens that actually could follow <expresssion_tail> if we use rule number 5. If we then see one of these tokens as the lookahead when we are about to expand <expression_tail>, we know to use rule 5. If we see anything else not covered in the table as our next lookahead token, we know that there is an error in the string we are parsing.
Computing the follow set for a nonterminal can be troublesome when we do it by hand, because it is easy to get lost. Essentially, to see what could follow <expression_tail>, we need to
1. Find every rule that has <expression_tail> on the right hand side. In general, there may be something in front of <expression_tail> and something behind <expression_tail>, since we are looking at the right hand side of the rules. That is, a right hand side of a rule that includes <expression_tail> will look like
<some_nonterminal> --> something_in_front <expression_tail> something_in_back2. Compute First(something_in_back). That is, the first tokens that can be reached by whatever is in back of <expression_tail> in such rules can follow <expression_tail>
Of course, something_in_back might be empty, too. That would mean that to find out what can follow <expression_tail> we need to look further, in this case to find out what can follow <some_nonterminal>, which is the nonterminal on the left hand side of the rule in which <expression_tail> appears on the right. And so the process continues.
Intuitively, looking at this grammar we see that one of the rules with <expression_tail> on the right is rule 2:
<expression> --> <term> <expression_tail>
Since there is nothing following <expression_tail> in this case, we must look further to see what could follow <expression>. Rule 1 has <expression> on the right hand side:
<start> --> <expression> eof
In this case, eof follows expression. We compute, therefore, First(eof). Since eof already is a token, we get that
First(eof) = { eof }
So, eof is in the follow set of <expression> and <expression_tail>.
Similarly, we see that <expression> is on the right hand side of rule 15:
<primary> --> ( <expression> )
Again, to compute the follow of <expression> (which we are doing to compute the follow of <expression_tail>) we find First of what is to the right of <expression> This is a right parenthesis. This gives
First( ) ) = { ) }
So, what we have discovered is that
Follow(<expression_tail>) = { eof ) }
So, the LL(1) table for row <expression_tail> looks like
| eof | + | - | * | / | ^ | identifier | integer_literal | ( | ) | |
| <start> | ||||||||||
| <expression> | ||||||||||
| <expression_tail> | 5 | 3 | 4 | 5 | ||||||
| <term> | ||||||||||
| <term_tail> | ||||||||||
| <factor> | ||||||||||
| <factor_tail> | ||||||||||
| <primary> |
If we are doing a top down, leftmost parse and we are about to expand <expression_tail>, if the lookahead is +,. we user rule 3, because we know it will lead to this lookahead token. If the lookahead is -, we apply rule 4, because we know it will lead to the lookahead token. If the lookahead is either an eof or a ), we appy rule 5, because even though application of rule 5 doesn't lead to an eof or a ) directly (it goes to lambda), we know that it is possible for an eof or ) to appear here if we apply rule 5, because an eof or a ) can follw <expression_tail>. If any other lookahead token is given, we know that the string we are parsing is in error, because this token cannot come from an application of rule 3 or rule 4, and even though rule 5 produces lambda, we know that no other token can follow <expression_tail>.