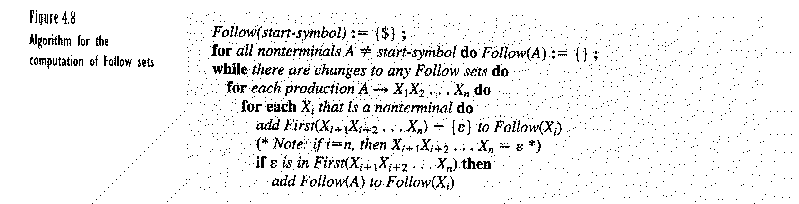
In this lecture we attempted to understand the First and Follow algorithms necessary for building a parse tree. We mainly just covered the First algorithm from the book. Both algorithms are reproduced at the bottom of this page. We applied the algorithm to the following two grammars.
There was no opportunity to include the full lecture here.
1. <start> --> <expression> eof 2. <expression> --> <expression> + <term> 3. <expression> --> <expression> - <term> 4. <expression> --> <term> 5. <term> --> <term> * <factor> 6. <term> --> <term> / <factor> 7. <term> --> <factor> 8. <factor> --> <factor> ^ <primary> 9. <factor> --> <primary> 10. <primary> --> identifier 11. <primary> --> integer_literal 12. <primary> --> ( <expression> )
0. <start> --> <expression> eof 1. <expression> --> <term> <expression_tail> 2. <expression_tail> --> + <term> <expression_tail> 3. <expression_tail> --> - <term> <expression_tail> 4. <expression_tail> --> l 5. <term> --> <factor> <term_tail> 6. <term_tail> --> * <factor> <term_tail>> 7. <term_tail> --> / <factor> <term_tail> 8. <term_tail> --> l 9. <factor> --> <primary> <factor_tail> 10. <factor_tail> --> ^ <primary> <factor_tail> 11. <factor_tail> --> l 12. <primary> --> identifier 13. <primary> --> integer_literal 14. <primary> --> ( <expression> )
We have examined the construction of the LL(1) table for a grammar intuitively, trying to figure out how we could determine which tokens predict which rules. Of course, in order for the process to be made precise, we need to find algorithms that help us with this process.
First consider a grammar that has no rules that produce the empty string. Then for any rule in the grammar of the form
A --> a, where a = X1X2...Xn and each Xi is a single symbol
to determine what tokens can be arrived at first from A we need to find First(X1).
An algorithm for doing this is
loop for each nonterminal A set First(A) = {} -- set First(A) to the empty set. end loop -- note that the empty set does not contain anything, -- not even e loop for each terminal a set First(a) = {a} end looploop while this is the first time through the loop, or any additions have been made to set First(A) for any A during the previous pass through the looploop through each rule in the grammar -- the current rule being processed has the general form A --> X1 X2...Xn -- where A is the nonterminal on the left, and each Xi represents a single -- symbol on the right, either a terminal or nonterminal.First(A) = First(A) union First(X1)end loop end loop
Things get a little more complex when empty string rules exist in the grammar. Why? Consider a general rule
A --> a, where a = X1X2...Xn
To compute First(A) we must find out what can come first from a (the right hand side of this rule). That would normally be First(X1) if there were no empty string rules in the grammar. In this case it is still First(X1), but if X1 can lead to the empty string, then we must union First(X1) to First(X2), and so on. We quit this union process when we reach an (Xi) that cannot derive the empty string. If the entire right hand side can derive the empty string (or is the empty string) then First(A) must also
The way to do this is to find First(A) for all nonterminals A (we know that First(a) for all terminals a is trivially just {a}.
let e stand for the empty string loop for each nonterminal A set First(A) = {} -- set First(A) to the empty set. end loop -- note that the empty set does not contain anything, -- not even e loop for each terminal a set First(a) = {a} end looploop for each rule in the grammar if the rule is A --> e then set First(A) = {e} end if end looploop while this is the first time through the loop, or any additions have been made to set First(A) for any A during the previous pass through the looploop through each non-e rule in the grammar -- the current rule being processed has the general form A --> X1 X2...Xn -- where A is the nonterminal on the left, and each Xi represents a single -- symbol on the right, either a terminal or nonterminal.k := 1 loop while k <= n First(A) = First(A) union (First(Xk) - {e}) if e is not in First(Xk) then exit this loop end if k := k + 1 end loop-- at this point we have finished examining the right hand side of the -- current rule. If we have discovered that every symbol on the right hand -- side can derive e, then that means that A can derive e as well, so we -- must add e to First(A). If not every symbol on the right hand side of -- this rule can derive e, then neither can A through application of this -- rule, so we should not include e in First(A) (although it might already -- be there for some other reason, and will not be removed) if k > n and e is in First(Xn) then set First(A) := First(A) union {e} end ifend loop throughend loop while-- at this point, first(A) has been computed for every nonterminal A, and -- First(a) has been set to {a} for each terminal a.
Try this algorithm with just the rules:
A --> Bc B --> b B --> e
How many times do you think the outermost while loop will run in the worst case?
If it turns out that First(A) contains e, this means that A can derive e, so then we also need to find what tokens could follow A, because the lookahead token returned from the scanner when we are about to expand A will have to come from some symbol that follows A.
The next algorithm is the Follow algorithm, which is also needed in constructing the LL(1) table. We didn't have time to cover it in this lecture.