Let's look at an example. Where in mPascal would we include actions symbols for inserting new identifiers into the symbol table? It would have to be in the variable declaration section. Those rules include
<VariableDeclarationPart> -> MP_VAR <VariableDeclaration>
MP_SCOLON <VariableDeclarationTail>
<VariableDeclarationPart> -> lambda
<VariableDeclarationTail> -> <VariableDeclaration> MP_SCOLON <VariableDeclarationTail>
<VariableDeclarationTail> -> lambda
<VariableDeclaration> -> <IdentifierList> MP_COLON <Type>
There is one problem here. The procedure corresponding to
IdentifierList is actually called from other locations as well, for example, in
parameter lists in procedure or function headers. The problem is that
procedure IdentifierList will not know without some help whether the identifiers
it matches are to be treated as variables to be placed into the symbol table or
as parameters to be handled differently.
<ValueParameterSection> -> <IdentifierList>
<VariableParameterSection> -> MP_VAR <IdentifierList>
Three possible solutions include:
- Change the rules of the grammar so that there are different id_list nonterminals for each different situation. For example, <var_id_list> could be a new nonterminal leading to rules that expand a list of identifiers that can only be encountered in a variable declaration section.
- Pass a semantic record to id_list whenever that procedure is called indicating from where the call was made. The information in this semantic record is called an "inherited attribute" of id_list, since it is inherited from rules farther up in the tree (e.g., the variable declaration rules).
- Just build a record that is a linked list of identifier lexemes, and pass this parameter back up to the procedure that called id_list. This record is the semantic information computed for nonterminal id_list. When the calling procedures get this information, they can then decide what to do with it (e.g., the variable declaration procedures would insert each lexeme in this linked list into the symbol table). The information in this semantic record is called a "synthesized attribute." This just means that the attribute was not inherited from above, but was constructed (i.e., synthesized) by this procedure or one below that was called by this procedure.
The last option is the only one that is feasible in the rules given above for variable declarations. For example, we can modify the <VariableDeclaration> rule as follows:
<VariableDeclaration> -> <IdentifierList> MP_COLON <Type> #insert(id_list, attributes)
The implication here is that by the time we have parsed this entire line we will have constructed the list of ids to be inserted into the symbol table as well as their type. So, we can then call a semantic routine to insert the ids into the symbol table along with their attributes (attributes "variable" and "integer" for example, depending on what is returned from type. There is an implicit understanding here that when <IdentifierList> is called, an empty list will be sent along and when the return from <IdentifierList> is accomplished, the id_list record will hold the list of the actual lexemes encountered. Similarly, an empty record will be sent along on the call to <Type> which will come back filled with the type parsed (e.g., integer). The attributes record will thus contain information about the kind of the ids (in this case "variable") and their types (e.g., integers). The call to insert will result in the ids in id_list being inserted into the symbol table with the appropriate attributes.
There are various approaches to symbol table implementation. One is the one we have given in class. In that case, each new scope requires a new symbol table that is placed on a stack of symbol tables. Once compilation of the part of the program corresponding to a scope (e.g., a procedure or function) is complete, its symbol table is discarded. A lookup of an identifier in a symbol table starts with the table on top of the stack and proceeds through table on the stack in order until the first occurrence of that identifier is found, or until the stack is exhausted (indicating and undefined identifier error). An illustrative example is given in the lecture notes for last time.
The book gives a different, but equivalent, approach. In this scheme, there is one symbol table structure for the entire program being compiled. As variables come into scope, they are inserted into this symbol table. When compilation of a scope (e.g., procedure or function) is complete, all of the identifiers in that scope are removed from the symbol table. The entire symbol table is implemented as one hash table, with new identifiers always inserted at the beginning of the hash chains in the symbol table. Thus, when a search is made for an identifier, the one encountered first in the chain (the most enclosing scope) will be found.
To see this, look at our example from last time. We were parsing
program Fred; var A, B, C : Integer;procedure A1(A : in Integer); var Q, X : Real; Ch : Character;function Snort(W : in Integer) return Integer; var X : Integer; begin -- Snort X := A + C; end Snortbegin -- A1 Write (Snort(C)); end A1;procedure Sort(A : in out List; N in Integer); begin X := 4.5; Sort(A, N/2); end;begin --Fred Write(A, X); end.
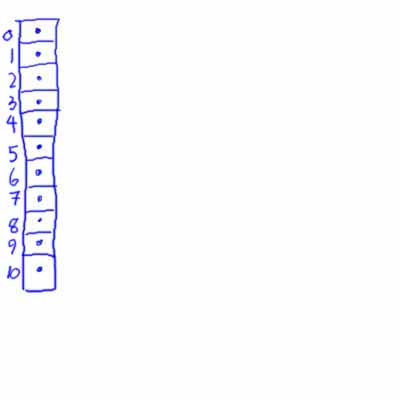
Our symbol table starts out as a large, empty hash table, say
The dots represent null pointers. Thus, this data structure is an array of pointers. The hash function we use for hashing lexemes would have the form
hash(lexeme) = f(lexeme) mod 11
Here, f is the main hash function. It would turn any ascii string into an integer value. Applying mod 11 to this value will turn it into a number between 0 and 10 (remember that mod, for positive integers) returns the remainder of dividing the left hand operand by the right hand operand), Thus, if we hash all of the identifiers in Fred as we encounter their declarations, we would get something like:

For example, the hash function applied to A1 yields 5, so we insert the lexeme A1 and its attributes into the symbol table at location 5.
At this point, we begin parsing the body of procedure A1. The symbol table would then look something like:
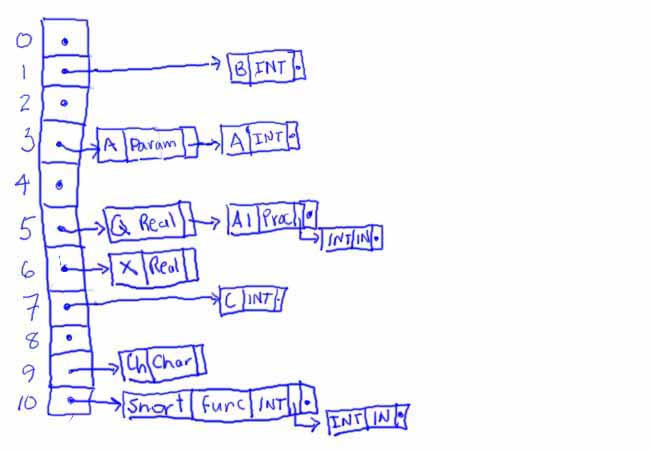
The main trick here is to insert the new values in this scope at the front of the list in the array element to which the new lexemes are hashed.. (Notice that we would need to have some indication of the scope level of each identifier stored with the identifier to be able to check for multiple declarations of the same identifier in this scope).
This brings us to the body of function Snort, which changes the symbol table to look like:
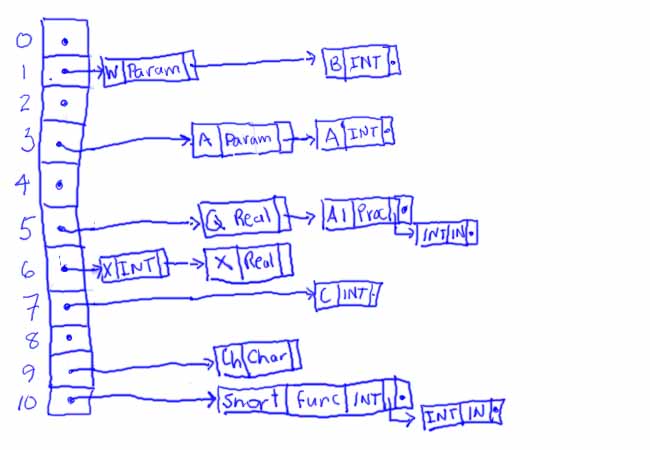
Now, when the compiler processes the line in Snort:
X := A + C;
it looks X, A, and C up by hashing each of these values. For example, X hashes to 6. The first entry for X in the chain beginning at location 6 is the proper one to use in this scope. Similarly for A and C.
After compiling all of Snort, though, we need a way to delete all of the entries in the scope for Snort as we continue parsing. This will require some special programming. For example, we could
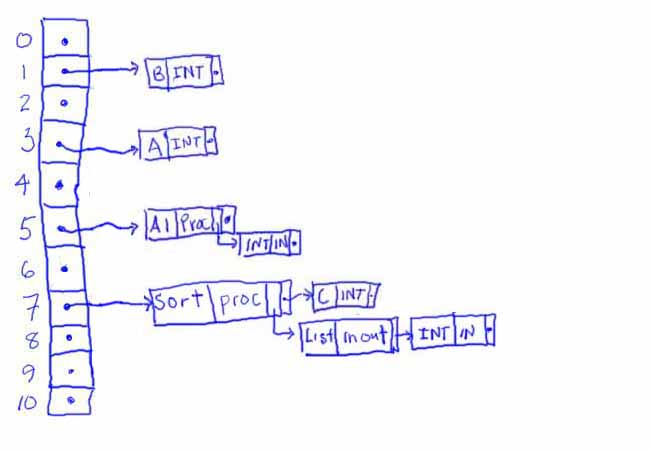
In all cases there will be some problems we don't need to worry about with the single symbol table per scope approach. The result of removing the elements in Snort's immediate scope gives:
Again, when we get done compiling the body of procedure A1, we must remove identifiers in its immediate scope, giving:
At this point we encounter procedure Sort in the line
procedure Sort(A : in out List; N in Integer);
At this point, identifier Sort must be entered into the symbol table for this (Fred's) immediate scope, giving:
Then we begin parsing procedure Sort, putting its identifiers into the symbol table at a new level, resulting in:
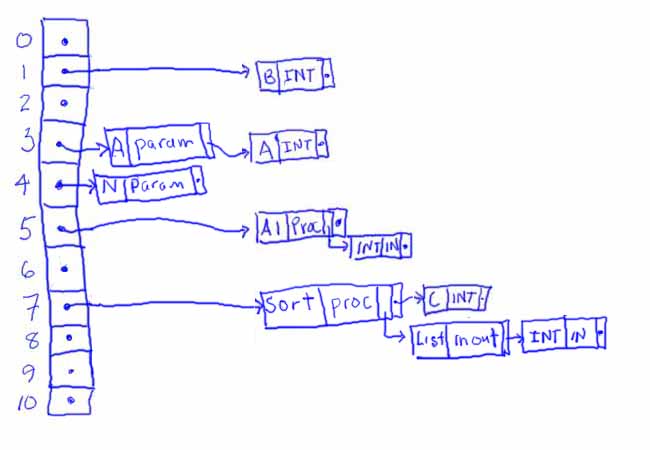
At the end of Sort, we again dump its local identifiers to get:
We use this version of the symbol table to complete the parse.