As mentioned last time, there are three things we need to know at least a little bit about when we begin doing semantic analysis in our compiler project. If we were not simultaneously learning about compiling and doing a project, we could perhaps study these things in succession. However, since we are writing a compiler at the same time as we are learning about compiling, we need to get at least an overview of the main issues to proceed.
The three things we have already mentioned are
There is one more thing we will now add to this list
We give a quick review here before proceeding.
The symbol table (section 6.3 in the textbook) is needed to hold semantic information about identifiers encountered during the program, including their lexeme, type (e.g., integer, real, array), kind (e.g., variable, constant, etc.), and other attributes (e.g., parameter). Scoping is represented by, for example, having a different symbol table for each scope and maintaining these as a stack of symbol tables as parsing progresses, pushing the new symbol table when a scope is entered and popping the symbol table when the scope is exited. One thing that is needed for eventual translation is the memory location where each identifier represented in the symbol table will eventually be stored when the translated program is run on the computer.
Run time memory management (chapter 7 in the textbook) gives us a model for memory that allows us to finish construction of the symbol table. In other words, this model lets us envision where each identifier will be eventually represented in memory. So, with this model in mind, we can include an entry in the symbol table for each identifier that indicates where that identifier will be in memory, so that we can generate the right addresses during translation. The most common memory management model uses a run time stack for managing variables. Each scope has its own activation record, which is pushed onto the stack when the scope is entered, and popped off when the scope is exited. Variables are located at fixed offsets from the start of the activation record for the scope.
In translating the source code to IR (covered differently in the book and not in depth), the semantic analyzer uses the symbol table to do type checking (to see that identifiers have been declared and used properly), and does the translation using the run time memory address information stored in the symbol table to generate correct addresses for the identifiers.
Error handling (not clearly identified in separate sections in the textbook) is the topic of this lecture.
The last point is important. There is no reason to be generating a translation of a program that has an error in it.
Catastrophic Mode: In this case, when an error is detected, an exception is raised, a message printed about where the error occurred and what it might be, and the entire compilation process is terminated.
Panic Mode: In this case, when an error is detected, the parser raises an exception that causes an error message to be printed about where the error occurred and what it might be, and also causes scanning to proceed to some delimiter, such as a semicolon, at which point parsing continues with the new construct. Just one delimiter can be chosen (e.g., the semicolon) as the synchronization token, or for more sophisticated approaches, a set of synchronizing tokens can be established based on the construct that is being parsed at the moment. For example, if an error is detected during the parse of an assignment statement, parsing would begin again with the statement following the next encountered semicolon if the semicolon is the synchronizing token. In this case, exceptions should be raised (thrown) and handled (caught) in the procedure where the synchronizing token is found so that parsing can be restarted at that point.
Non-Panic Mode: In this mode, the parser pretends not to panic quite so much and attempts to restart the parse at some point sooner than the next delimiter (after raising an exception and posting an appropriate error message).
Error Repair Mode: In this instance, the parser actually tries to repair the code so that the construct in which the error was found can continue to be parsed. Of course, the repair is likely not correct. The point is not to produce a correct program (although there were early attempts to do this) but to be able to continue the parsing process and be able to parse as much of the program as possible. So, for example, a common repair technique is to insert a semicolon wherever it might appear that one is missing.
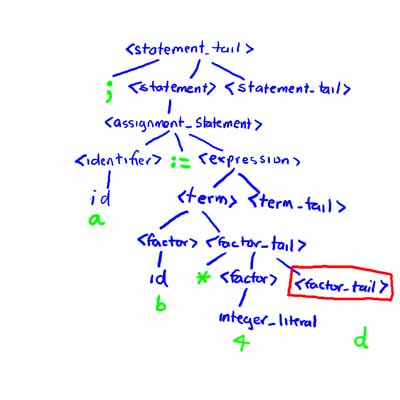
Suppose you are parsing the statement
a := b * 4 d * (a + b);
In this case there appears to be an operator missing between c and 4. In this instance, our parse would look something like
Notice that we are trying to expand <factor_tail>, but the lookahead is an id. This, according to our LL(1) table, is impossible, so we have an error.
In panic mode error recovery, we basically throw this statement away and try to parse the next statement instead. In other words, we back up to the most recent <statement> nonterminal in our tree, skip past all tokens until we see the semicolon, and then restart the parse from <statement> according to the rule
<statement_tail> --> ; <statement> <statement_tail>
(Of course, this only applies to this grammar.)
In our parser, this same thing can be accomplished by rasing a Syntax_Error exception any time while parsing from procedure Statement. This exception is then propagated back up until procedure Statement is reached. At that point, the exception is handled by printing a proper error message, such as
Expected an operator or delimiter, but found an identifier at line 35 column 33. Skipping until after next semicolon.
Then the exception handler would repeatedly call the scanner until the next token after the next semicolon is reached. Finally, the exception handler would then make sure that procedure Statement begins afresh at this point with this new lookahead. So, if we were parsing the three statements
.
.
.
read (a, b, d);
a := b * 4 d * (a + b);
write(a);
.
.
.
the read statement would parse properly. The parser would then encounter an error in processing the assignment statement (as shown above). If the panic mode error recovery is used and the synchronizing token is the semicolon, the tokens d, *, (, a, +, b, and ) would be scanned and skipped. Parsing would then restart at the semicolon in the above rule for statement tail, and the call to <statement> would then result in a proper parse for the write statement.
In this case, catastrophic mode would terminate parsing after the scanner returned the ID Sugar. Panic mode with scanning restarting after the semicolon would work pretty well in this case. Non-panic mode might restart parsing with Sugar, assuming that Sugar is the start of a new statement, which would lead to cascading errors (because then it might try to restart with Yeast after the next error is encountered, and so on). Error repair might try to fix the construct by inserting a semicolon after Grapes and treating Sugar as the start of a new assignment statement, again leading to cascading errors.Malt := Oranges + Grapes Sugar * Yeast;
where C is an undeclared variable. In this case, the action #process_id(ID_Rec) would discover this fact and return an error in ID_Rec (that is, it would return the variant of the record that is an error record, or it would accomplish the same thing by raising an exception). The semantic action for gen_infix should at this point be called by the parser to do B*C. However, with one valid semantic record and one error record, gen_infix would just return an error record itself, representing the intermediate value for B*C. Similarly, gen_infix for A+T, where T is the semantic record for the temporary value (in this case, an error semantic record) would return an error record. Finally, gen_assign would have a semantic record for X and the error semantic record for the right hand side, and so it, too, would not generate code. In this case, no semantic record is returned from gen_assign, so the parser just continues, by parsing the next statement normally. Similar things can be accomplished with exceptions, in which the exception is passed back until the parser starts on the next statement.X := A + B * C;